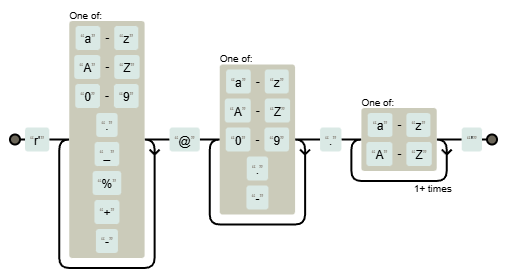
对正则表达式的字符进行的整理
常见字符
普通字符
普通字符按照字面意义进行匹配,例如匹配字母 “a” 将匹配到文本中的 “a” 字符。、
元字符
元字符具有特殊的含义, 它们不表示字面意义,而是用于控制匹配模式 例如 \d 匹配任意数字字符,\w 匹配任意字母数字字符,. 匹配任意字符(除了换行符)等。
¡ 【abc】:匹配 […] 中的所有字符,例如 [aeiou] 匹配字符串 “google runoob taobao” 中所有的 e o i u a 字母。
¡ 【^abc】:匹配除了 […] 中字符的所有字符,例如 [^aeiou] 匹配字符串 “google runoob taobao” 中除了 e i o u a 字母的所有字符。
¡ 【a-z】:表示一个区间,匹配所有小写字母,【A-Z】匹配大写字母
¡ . :匹配换行符(\n,\r)之外的任何单个字符,与【^\n\r】相等
¡ 【\sS】:匹配所有。\s是匹配所有空白符,包括换行,、\S非空白符,不包括换行
¡ \w:匹配字母,数字,下划线。等价于【A-Za-z0-9_】
¡ \d:匹配任意一个阿拉伯数字(0到9)。等价于【0-9】
注:
简单来说,断言就是"条件",它要求目标字符串必须满足某些条件,但不会消耗字符。(?=…)(正向肯定预查)
匹配后面跟着特定模式的位置
示例:Windows(?=95|98) 匹配后面跟着95或98的"Windows"
(?!…)(正向否定预查)
匹配后面不跟着特定模式的位置
示例:Windows(?!95|98) 匹配后面不跟着95或98的"Windows"
(?<=…)(反向肯定预查)
匹配前面是特定模式的位置
示例:(?<=95|98)Windows 匹配前面是95或98的"Windows"
(?<!…)(反向否定预查)
匹配前面不是特定模式的位置
示例:(?<!95|98)Windows 匹配前面不是95或98的"Windows"
限定符:量词
*:匹配前面的模式零次或多次。
+:匹配前面的模式一次或多次。
?: 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ? 。
{n}:匹配前面的模式恰好 n 次。
{n,}:匹配前面的模式至少 n 次。
{n,m}:匹配前面的模式至少 n 次且不超过 m 次,贪婪字符。若想尽可能少,{n,m}?
注:*和+ ,?,{}限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配
字符类元字符
[ ]:匹配括号内的任意一个字符。例如,[abc] 匹配字符 “a”、“b” 或 “c”。
[^ ]:匹配除了括号内的字符以外的任意一个字符。例如,[^abc] 匹配除了字符 “a”、“b” 或 “c” 以外的任意字符。
定位符:边界匹配
^:匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。与\A同,要匹配 ^ 字符本身,请使用 ^ 。
$:匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。与\Z同,要匹配 $ 字符本身,请使用 $ 。
\b:匹配单词边界, 即字与空格间的位置。
\B:匹配非单词边界。
\A:左边界
\Z:右边界
( ):用于分组和捕获子表达式。 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )
(?: ):用于分组但不捕获子表达式。
特殊字符
l \: 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ’n’ 匹配字符 ’n’。’\n’ 匹配换行符。序列 ‘\’ 匹配 “",而 ‘(’ 则匹配 “(” 。
l .:匹配任意字符(除了换行符)。
l |:用于指定多个模式的选择。
注:
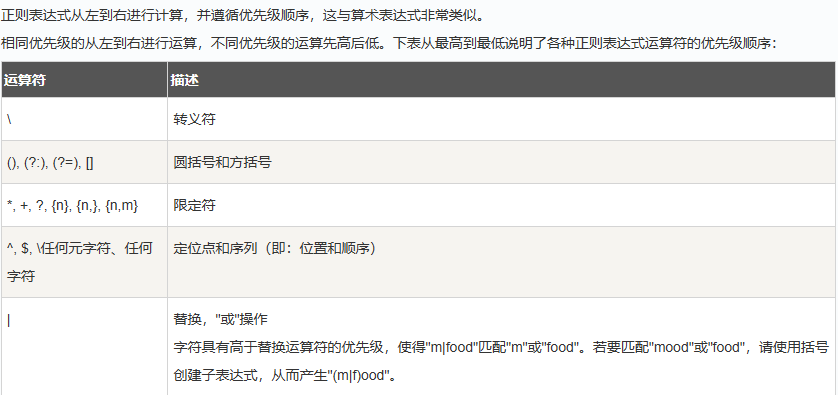
修饰符
正则表达式修饰符(也称为模式修饰符或标记)是用于改变正则表达式匹配行为的特殊指令。
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下:
使匹配不区分大小写
示例:/abc/i 可以匹配 “abc”, “Abc”, “ABC” 等
支持语言:几乎所有正则表达式实现(JavaScript、PHP、Python等)
查找所有匹配项,而不是在第一个匹配后停止
示例:在字符串 “ababab” 中,/ab/g 会匹配所有三个 “ab”
支持语言:JavaScript、PHP等
改变 ^ 和 $ 的行为,使其匹配每行的开头和结尾,而不仅是整个字符串的开头和结尾
示例:在多行字符串中,/^abc/m 会匹配每行开头的"abc”
支持语言:JavaScript、PHP、Python、Perl等
使点号 . 匹配包括换行符在内的所有字符
在JavaScript中称为"dotall"模式,使用 /s 修饰符
示例:/a.b/s 可以匹配 “a\nb”
支持语言:PHP、Perl、Python(作为re.DOTALL)、JavaScript(ES2018+)
启用完整的Unicode支持
正确处理UTF-16代理对和Unicode字符属性
示例:/\p{Script=Greek}/u可以匹配希腊字母
支持语言:JavaScript、PHP等
从目标字符串的当前位置开始匹配(使用lastIndex属性)
类似于^锚点,但针对的是匹配的起始位置
示例:在JavaScript中,/a/y 会从lastIndex开始匹配 “a”
支持语言:JavaScript
忽略模式中的空白和注释,使正则表达式更易读
示例:在PHP中,/a b c/x 等同于 /abc/
支持语言:PHP、Perl、Python(作为re.VERBOSE)