
Numpy是Python的处理数据的库,学习Numpy可以更深入的了解Pandas
numpy ndarray对象
n维数组对象ndarray是一系列同类型数据的集合
创建一个ndarray:
(1)numpy.array(object,dtype = None, copy = True, order = None, subok = False, ndmin = 0)
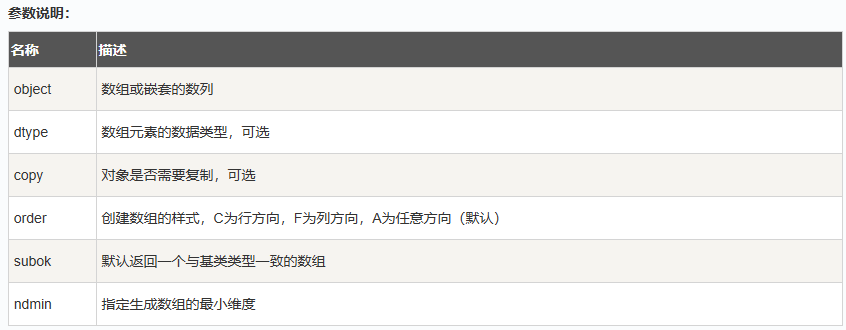
(2)np.asarray(a, dtype = None, order = None)
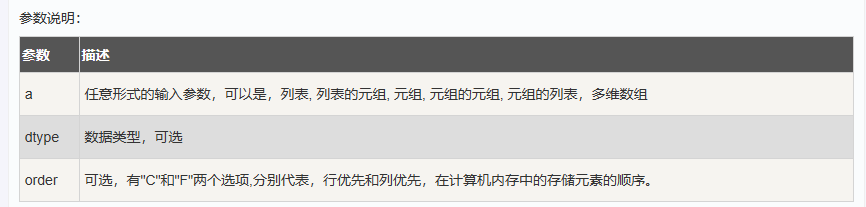
numpy.array 与 numpy.asarray 区别
numpy.array 和 numpy.asarray 都可以将输入数据转换为 ndarray,但两者的主要区别在于:
内存行为:
当数据源是一个 ndarray 时:
¡ np.array 会复制数据,创建一个新的副本,占用额外内存。
¡ np.asarray 不会复制数据,而是直接使用原数据的内存。
应用场景:
l 使用 np.array 时,不论数据源为何,总是返回一个独立的副本。
l 使用 np.asarray 时,如果数据源已经是 ndarray,它只是返回一个引用,不会进行复制。
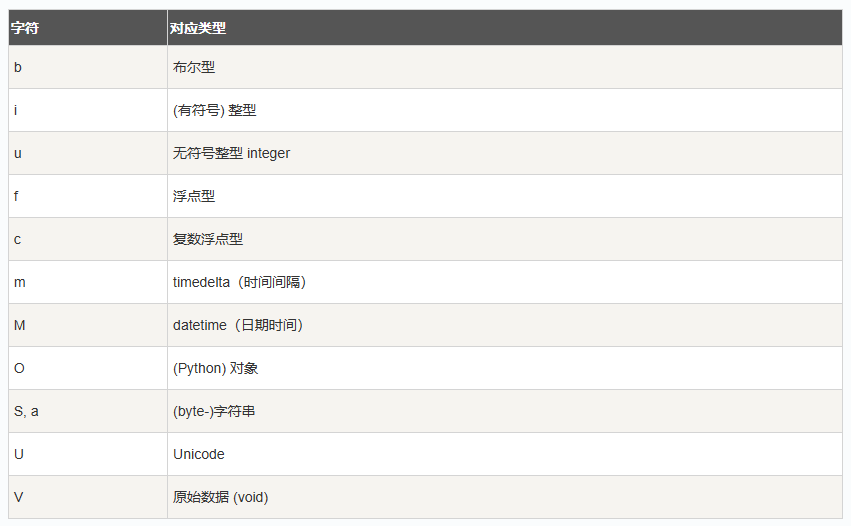
numpy数据类型
通过numpy.dtype()可以赋予改变ndarray类型
numpy数组属性
numpy.reshape()改变数组大小,并且返回的是视图,若想返回副本,需要numpy.reshape().copy()

创建数组
numpy.arange( start, stop, step, dtype ).reshape( n, n )
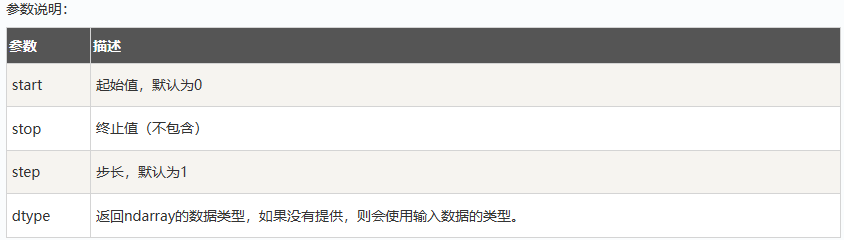
等差数列:np.linspace(start, stop, num=50,endpoint=True, retstep=False, dtype=None)
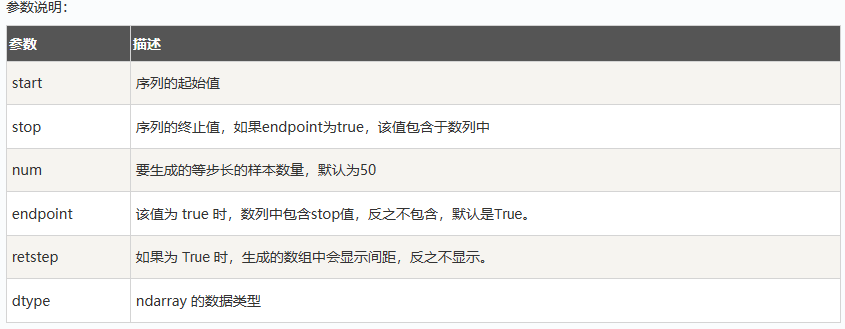
等比数列:np.logspace(start, stop, num=50,endpoint=True, base=10.0, dtype=None)

numpy.ones( n )、numpy.zeros(n)、numpy.empty(不常用)
补充:np.zeros.like()、np.ones.like()、random.randn()、random.randint (start,stop,size)
np.eye输出:
n [[1. 0. 0. 0. 0.]
n [0. 1. 0. 0. 0.]
n [0. 0. 1. 0. 0.]
n [0. 0. 0. 1. 0.]
n [0. 0. 0. 0. 1.]]
切片和索引
切片:ndarray[ start:stop:step]
索引:
整数数组索引: 整数数组索引是指使用一个数组来访问另一个数组的元素。这个数组中的每个元素都是目标数组中某个维度上的索引值。
布尔索引: 布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
花式索引:花式索引指的是利用整数数组进行索引。花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。
对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素,如果目标是二维数组,那么就是对应下标的行。
花式索引跟切片不一样,它总是将数据复制到新数组中。
np.ix_(): np.ix_ 函数就是输入两个数组,产生笛卡尔积的映射关系。例如 A={a,b}, B={0,1,2},则:
A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
广播机制
对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
l 数组拥有相同形状。
l 当前维度的值相等。
l 当前维度的值有一个是 1。
若条件不满足,抛出"ValueError: frames are notaligned"异常。
tile():就是将原矩阵横向、纵向地复制。以行方向复制三倍,列方式复制两倍:tile(a,(3,2))
迭代器
np.nditer(a,order=“c/f”)
迭代数组:for i in np.nditer(a): print(i)