
对数组内数据进行处理,针对数据类型分别整理总结
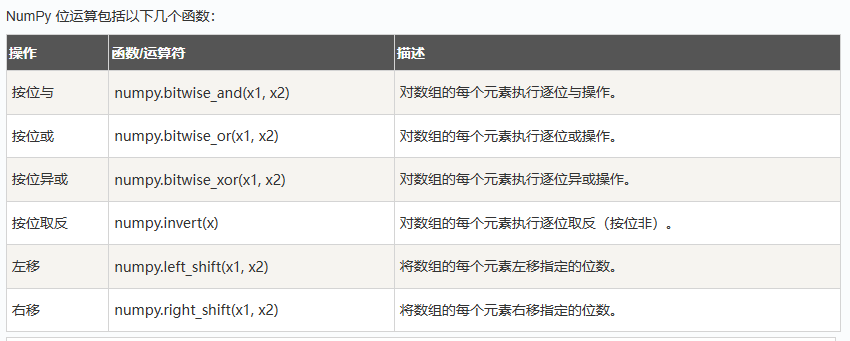
位函数

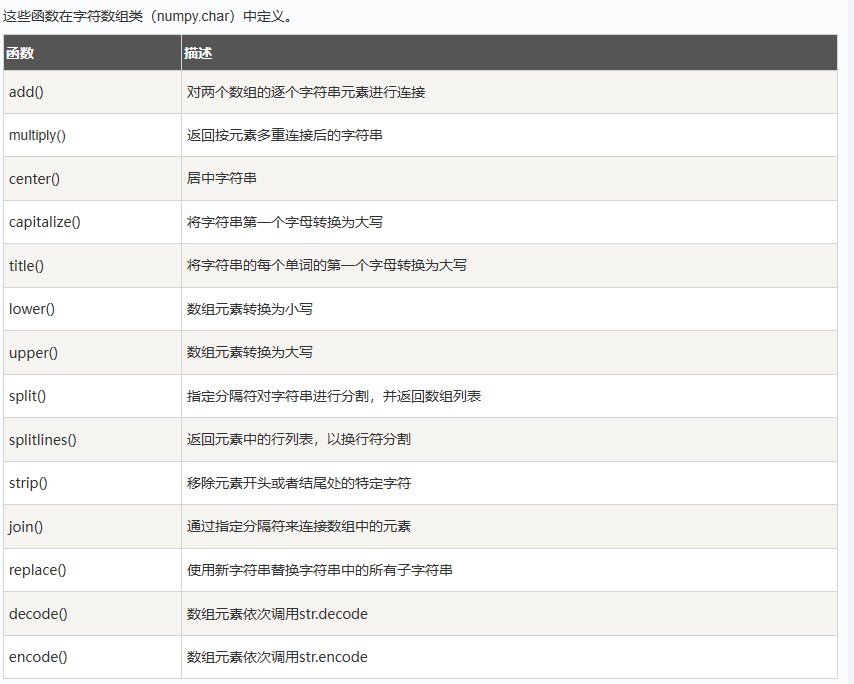
字符串函数
三角函数
标准的三角函数:sin()、cos()、tan()
反三角函数:arcsin,arccos,和 arctan 返回给定角度的 sin,cos 和 tan 。
这些函数的结果可以通过numpy.degrees()函数将弧度转换为角度。
四舍五入函数
numpy.around(a,decimals)
函数返回指定数字的四舍五入值。
参数说明:
a: 数组
decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置
numpy.floor()
返回小于或者等于指定表达式的最大整数,即向下取整
numpy.ceil()
返回大于或者等于指定表达式的最小整数,即向上取整
简单计算函数
add(),subtract(),multiply()和divide()
简单的加减乘除
numpy.reciprocal()
函数返回参数逐元素的倒数。如1/4倒数为4/1。
numpy.power()
函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂
numpy.mod()
计算输入数组中相应元素的相除后的余数。 注:函数 numpy.remainder() 也产生相同的结果。
统计函数
numpy.amin(a,axis=None, out=None, keepdims=
用于计算数组中的元素沿指定轴的最小值。
参数说明:
¡ a: 输入的数组,可以是一个NumPy数组或类似数组的对象。
¡ axis: 可选参数,用于指定在哪个轴上计算最小值。如果不提供此参数,则返回整个数组的最小值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
¡ out: 可选参数,用于指定结果的存储位置。
¡ keepdims: 可选参数,如果为True,将保持结果数组的维度数目与输入数组相同。如果为False(默认值),则会去除计算后维度为1的轴。
¡ initial: 可选参数,用于指定一个初始值,然后在数组的元素上计算最小值。
¡ where: 可选参数,一个布尔数组,用于指定仅考虑满足条件的元素。
numpy.amax()
用于计算数组中的元素沿指定轴的最大值。
参数说明:
¡ initial: 可选参数,用于指定一个初始值,然后在数组的元素上计算最大值。
numpy.extract()
函数根据某个条件从数组中抽取元素,返回满条件的元素。
numpy.ptp(a, axis=None, out=None, keepdims=
函数计算数组中元素最大值与最小值的差(最大值 - 最小值)。
参数说明:
¡ a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象。
¡ axis: 可选参数,用于指定在哪个轴上计算峰-峰值。如果不提供此参数,则返回整个数组的峰-峰值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
¡ out: 可选参数,用于指定结果的存储位置。
¡ keepdims: 可选参数,如果为 True,将保持结果数组的维度数目与输入数组相同。如果为 False(默认值),则会去除计算后维度为1的轴。
¡ initial: 可选参数,用于指定一个初始值,然后在数组的元素上计算峰-峰值。
¡ where: 可选参数,一个布尔数组,用于指定仅考虑满足条件的元素。
numpy.percentile(a, q, axis)
百分位数是统计中使用的度量,表示小于这个值的观察值的百分比
参数说明:
¡ a: 输入数组
¡ q: 要计算的百分位数,在 0 ~ 100 之间
¡ axis: 沿着它计算百分位数的轴
numpy.median(a, axis=None,out=None, overwrite_input=False, keepdims=
用于计算数组 a中元素的中位数(中值)
参数说明:
¡ a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象。
¡ axis: 可选参数,用于指定在哪个轴上计算中位数。如果不提供此参数,则计算整个数组的中位数。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
¡ out: 可选参数,用于指定结果的存储位置。
¡ overwrite_input: 可选参数,如果为True,则允许在计算中使用输入数组的内存。这可能会在某些情况下提高性能,但可能会修改输入数组的内容。
¡ keepdims: 可选参数,如果为True,将保持结果数组的维度数目与输入数组相同。如果为False(默认值),则会去除计算后维度为1的轴。
numpy.mean(a, axis=None, dtype=None,out=None, keepdims=
函数返回数组中元素的算术平均值,如果提供了轴,则沿其计算。
注:算术平均值是沿轴的元素的总和除以元素的数量。
参数说明:
¡ a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象。
¡ axis: 可选参数,用于指定在哪个轴上计算平均值。如果不提供此参数,则计算整个数组的平均值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。
¡ dtype: 可选参数,用于指定输出的数据类型。如果不提供,则根据输入数据的类型选择合适的数据类型。
¡ out: 可选参数,用于指定结果的存储位置。
¡ keepdims: 可选参数,如果为True,将保持结果数组的维度数目与输入数组相同。如果为False(默认值),则会去除计算后维度为1的轴。
numpy.average()
函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
该函数可以接受一个轴参数。 如果没有指定轴,则数组会被展开。
加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
考虑数组[1,2,3,4]和相应的权重[4,3,2,1],通过将相应元素的乘积相加,并将和除以权重的和,来计算加权平均值。
标准差:标准差是一组数据平均值分散程度的一种度量。标准差是方差的算术平方根。标准差公式如下:std = sqrt(mean((x - x.mean())**2))
统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数, 标准差是方差的平方根。即 mean((x - x.mean())** 2)。
排序函数
numpy.sort(a, axis,kind, order)
函数返回输入数组的排序副本
参数说明:
¡ a: 要排序的数组
¡ axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序
¡ kind: 默认为’quicksort’(快速排序)
¡ order: 如果数组包含字段,则是要排序的字段
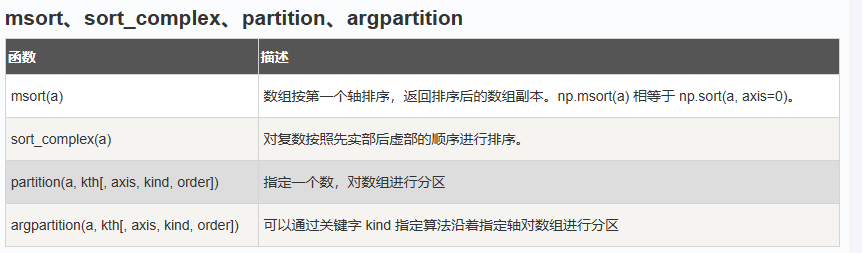
注:np.msort()已弃用
np.partition()
排序用以下示例解释
假设a= np.array([3, 4, 2, 1]) ,执行np.partition(a, 3)
将数组 a 中所有元素(包括重复元素)从小到大排列,3 表示的是排序数组索引为 3 的数字,比该数字小的排在该数字前面,比该数字大的排在该数字的后面
假设a = array([2, 1, 3, 4]),执行np.partition(a, (1, 3))
小于 1 的在前面,大于 3 的在后面,1和3之间的在中间,输出array([1, 2, 3, 4])
numpy.lexsort()
用于对多个序列进行排序。把它想象成对电子表格进行排序,每一列代表一个序列,排序时优先照顾靠后的列。
这里举一个应用场景:小升初考试,重点班录取学生按照总成绩录取。在总成绩相同时,数学成绩高的优先录取,在总成绩和数学成绩都相同时,按照英语成绩录取…… 这里,总成绩排在电子 表格的最后一列,数学成绩在倒数第二列,英语成绩在倒数第三列。
索引函数
numpy.argsort()函数返回的是数组值从小到大的索引值。
numpy.argmax() 和 numpy.argmin()函数分别沿给定轴返回最大和最小元素的索引。
numpy.nonzero() 函数返回输入数组中非零元素的索引。
numpy.where() 函数返回输入数组中满足给定条件的元素的索引。
线性代数
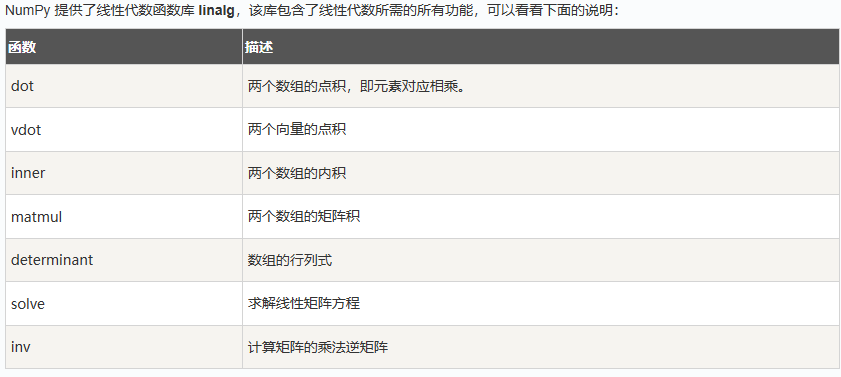
numpy.linalg.det()
numpy.linalg.det() 函数计算输入矩阵的行列式。
行列式在线性代数中是非常有用的值。 它从方阵的对角元素计算。 对于 2×2 矩阵,它是左上和右下元素的乘积与其他两个的乘积的差。
换句话说,对于矩阵[[a,b],[c,d]],行列式计算为 ad-bc。 较大的方阵被认为是 2×2 矩阵的组合。
random随机函数
固定从[0,1)之间抽取
np.random.rand(维度)
rand函数根据给定维度生成 [0,1)之间的浮点数,包含0,不包含1
类似的是np.random.random()=np.random.sample()=np.random.random_sample()
np.random.randn(维度)
randn函数返回一个或一组样本的浮点数,具有标准正态分布
类似的random.normal(loc=0,scale=1,size维度),不同的是norma会默认均值loc,标准差scale
从给定范围内抽取
np.random.randint(star,end=none,size=none)
返回随机整数,范围是 [star,end),size是维度
类似的是np.random.uniform(),也是在范围内随机,但不是整数
np.random.choice(a,size=none,replace=Ture,p=none)
从给定的一维数组中抽取元素,a为一维数组或整数,p为出现的概率(数组,为a所有元素赋予概率),a为整数时,相当于np.arange()
replace=false时,给定的随机数不能重复
np.random.seed()
赋予随机种子