
数据分析的数据预处理部分
1.数据清洗
1.1 缺失值处理: 识别并填补缺失值,或删除含缺失值的行/列。
删除包含空字段的行
df.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
参数说明:
-
axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
-
how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
-
thresh:设置需要多少非空值的数据才可以保留下来的。
-
subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
-
inplace:若设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
注:用pd.isnull()来判断是否有空值
替换空字符
df.fillna(替换值,inplace=false)
Pandas使用mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数),常用这三种方法替换空值
注:df.replace(old_value,new_value)将指定值替换为新值
1.2 异常值处理:
识别并替换异常值,或删除异常值的行/列。
异常值分析方法
简单统计量分析:最常用的方法就是分析最大值最小值
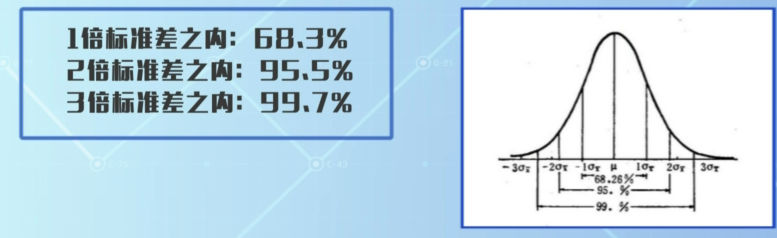
3δ准则:正态分布3倍标准差之外为异常,例如标准差2,平均值10,那4-16之间的值为有效值 (读音:三 德尔塔)
df
= df[abs(df-df.mean())> 3*df.std()] #
每个值都判断一次 ,输出一个dataframe表,有True就是有异常值
箱型图分析:箱型图外部为异常

df.plot(kind = “box”)#绘制箱线图
1.3 重复数据处理:检查并删除重复数据,确保每条数据唯一
删除重复数据的行
df.drop_duplicates()
注:用df.duplicates()来判断是否有重复值
1.4 数据格式转换:转换数据类型或进行单位转换,如日期格式转换。
字符串–日期格式转换
pd【列名】.to_datetime()
注:可以利用pd.Timedelta(days=)进行时间的加减
格式转换
pd【列名】.astype()
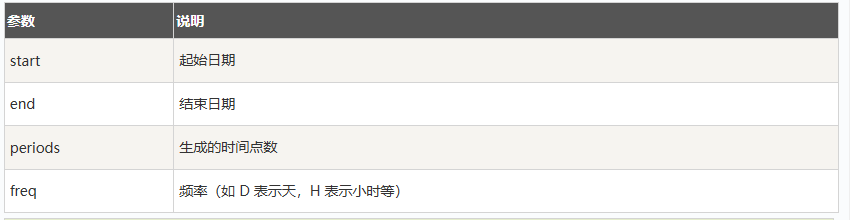
生成时间序列
date_range()
1.5 文本处理:
对文本数据进行清洗,如去除停用词、词干化、分词等
去除停用词,去除不想要的词,如“the”“is”
自定义函数(基于 nltk 或 spaCy)
提取词干或恢复单次的基本形式
nltk.stem.PorterStemmer()
将文本分割成单词或字词
nltk.word_tokenize()
2.数据集成
2.1 数据排序
根据列的值进行排序
sort_values( by=,ascending=True)
按照指定的列(by)排序,ascending 控制升序或降序,默认为升序
根据行或列的索引进行排序
sort_index( axis=0)
按照行或列的索引排序,axis 控制按行或列排序
2.2 数据聚合
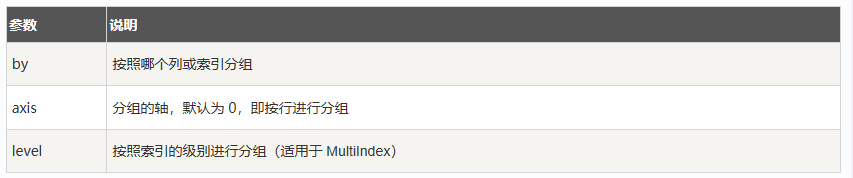
按列分组并聚合
df.groupby(by).agg()
按指定列(by)进行分组,agg() 可以传入不同的聚合函数,进行多种操作
分组groupby()
聚合agg()

多重聚合函数应用
df.groupby(by).agg([func1, func2])
可以对同一列应用多个聚合函数,返回多种聚合结果
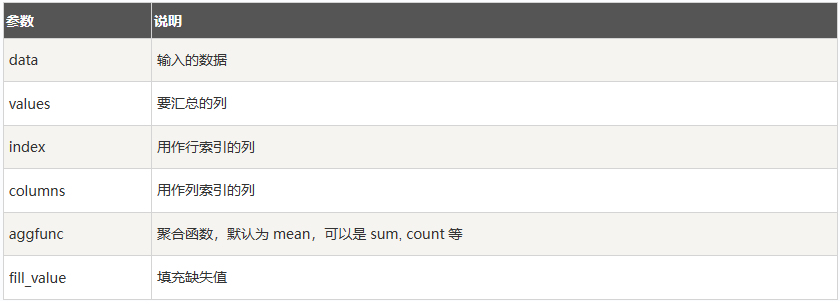
透视表
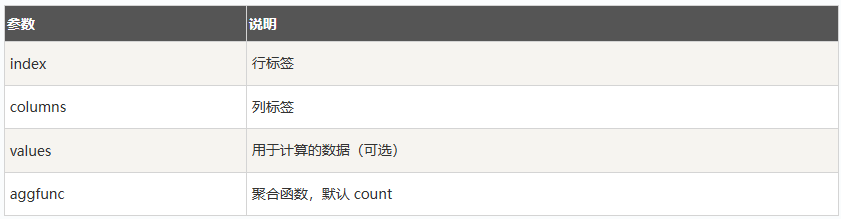
pd.pivot_table(data,values,index, columns, aggfunc)
用指定的列进行行、列分类汇总,values 是需要聚合的值,aggfunc 是聚合函数
交叉表
pd.crosstab()
2.3 数据合并
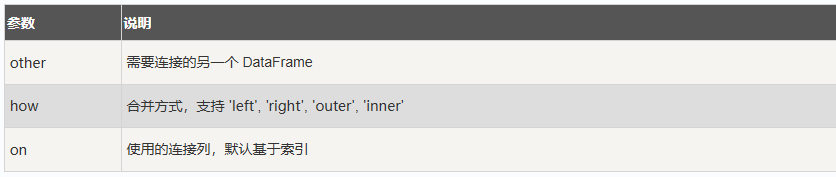
数据库风格的连接
merge() 方法允许根据某些键值对两个 DataFrame 进行合并,类似SQL 中的 JOIN 操作。支持内连接(两个键值对的交集),外左连接和外右连接

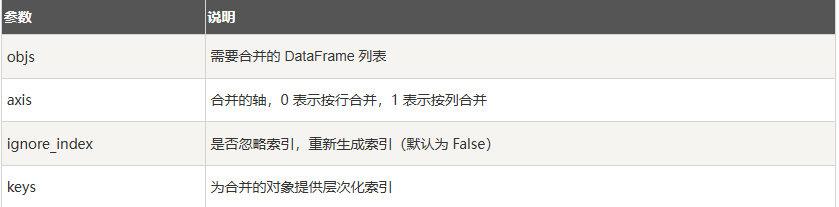
沿轴连接
concat()用于将多个 DataFrame 沿指定轴(行或列)进行连接堆叠,常用于行合并(asix=0)或列合并()
基于索引连接
join() 方法是Pandas 中的简化连接操作,通常用于基于索引将多个 DataFrame 连接
3 数据变换: 把数据变成适合的样式。
3.1 规范化:
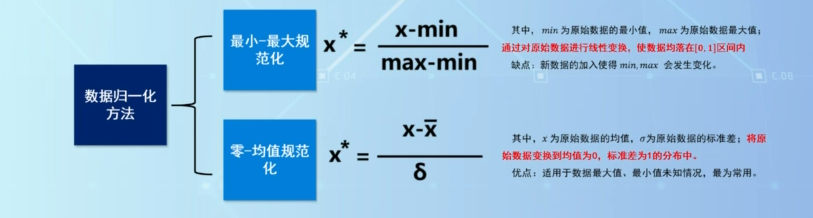
最小最大规范化,归一化(Min-Max):将数据缩放到指定的范围(如 [0, 1])。
1、 MinMaxScaler()
2、(df-df.min()/(df.max()-df.min()))
3、from sklearnimport preprocessing
min_max_scaler = preprocessing.minmax_scale(df)
零-均值规范化,标准化(Z-score):将数据转换为均值为0,标准差为1的分布
1、 StandardScaler()
2、(df-df.mean())/df.std()
3、scaler = preprocessing.scale(df)
小数定标规范化:移动小数点位置,落在 [-1,1]之间:
df/10**np.ceil(np.log10(df.abs().max()))
3.2 连续属性离散化: 将连续的数据进行分段,使其变为一段段离散化的区间
分箱(binning):等宽法,等频法
等宽法 pd.cut(x,bins,labels = )
#参数说明
-
x :需要分箱的一维数组或Series
-
bins:分箱的边界。可以是一个整数,表示要分的区间数量,或者是一个序列,表示每个区间的边界。
-
right:布尔值,默认为 True,表示区间是否包含右边界。
-
labels:可选参数,用于指定每个区间的标签。如果提供的标签数量与区间数量不一致,会抛出异常。
-
retbins:布尔值,默认为 False,表示是否返回用于分箱的边界。
-
precision:整数,默认为 3,表示返回区间的精度。
-
include_lowest:布尔值,默认为False,表示是否将最低值包含在第一个区间内。
等频法pd.qcut(x,q,labels = )
参数说明:
-
x:需要分箱的一维数组或 Series。
-
q:分箱的数量,可以是一个整数,或是一个 0 到 1 之间的序列。
-
labels:可选参数,用于指定每个区间的标签。
-
retbins:布尔值,默认为 False,表示是否返回用于分箱的边界。
-
precision:整数,默认为3,表示返回区间的精度。
-
duplicates:字符串,默认为‘raise’,当边界中有重复值时的行为。可以是 ‘raise’(抛出异常)、‘drop’(删除重复的边界)或 ‘ignore’(忽略重复的边界)。
3.3 特征二值化(binarization):
from sklearn.preprocessing import Binarizer
Binarizer (threshold = num).fit_transform(x)
4 数据规约
对属性和数值进行规约获得一个比原数据集小的规约表示,但扔接近原数据的完整性,对规约后数据集挖掘可产生近乎相同的分析结果
4.1 属性规约 :通过减少数据集的维度
方法:向前选择,向后删除,决策树,PCA
PCA(主成分分析法)
form sklearn.decomposition import PCA
pca = PCA(n_components = none) #设定保留的特征数,默认为none,全保留;“mle”会自动选取特征数量;
pca.fit(data)
注:用pca.explained_variance_ratio_ 计算每个特征的贡献率(方差百分比)
4.2 数值规约:减少数据集的记录数
有参方法:回归法(线性模型)
无参方法:直方图,聚类,抽样
直方图:用分箱表示数据分布,每个箱子代表一个属性(频率对)
plt.hist(data,bins = )
数据抽样:从数据集中抽取样本,或通过过采样/欠采样处理类别不平衡
随机抽样
df.sample(n = num , replace = False)#不放回抽样,默认为False
df.sample(n= num , replace = True) #放回抽样
分层抽样
可以先分层,通过添加一列不同数值的随机数据
df ( df[ ]==num ) .sample(frac= num , replace = False) #不放回抽样,默认为False;frac为0-1的小数,代表抽取百分比
df ( df[ ]== num ) .sample(frac= num , replace = True) #放回抽样