
数据分析的提取数据部分
CSV
读取文件:pd.read.csv()
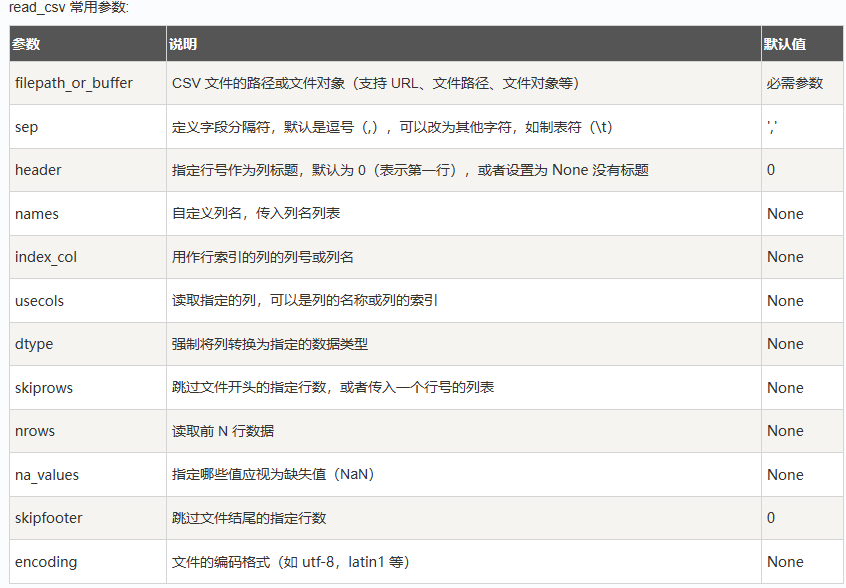
存储文件:to_csv()
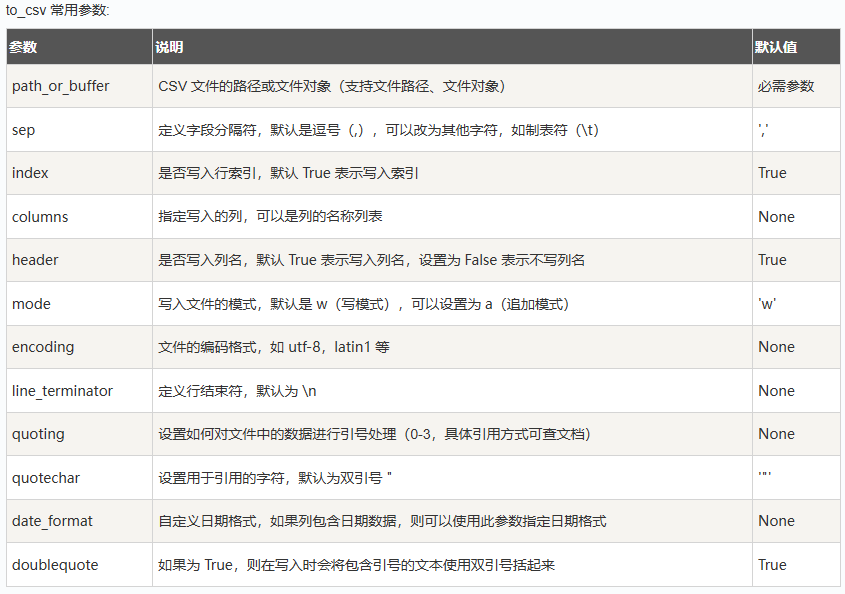
Excel
读取文件:pd.read.excel()
参数说明:
-
io:这是必需的参数,指定了要读取的 Excel 文件的路径或文件对象。
-
sheet_name=0:指定要读取的工作表名称或索引。默认为0,即第一个工作表。
-
header=0:指定用作列名的行。默认为0,即第一行。
-
names=None:用于指定列名的列表。如果提供,将覆盖文件中的列名。
-
index_col=None:指定用作行索引的列。可以是列的名称或数字。
-
usecols=None:指定要读取的列。可以是列名的列表或列索引的列表。
-
dtype=None:指定列的数据类型。可以是字典格式,键为列名,值为数据类型。
-
engine=None:指定解析引擎。默认为None,pandas会自动选择。
-
converters=None:用于转换数据的函数字典。
-
true_values=None:指定应该被视为布尔值True的值。
-
false_values=None:指定应该被视为布尔值False的值。
-
skiprows=None:指定要跳过的行数或要跳过的行的列表。
-
nrows=None:指定要读取的行数。
-
na_values=None:指定应该被视为缺失值的值。
-
keep_default_na=True:指定是否要将默认的缺失值(例如NaN)解析为NA。
-
na_filter=True:指定是否要将数据转换为NA。
-
verbose=False:指定是否要输出详细的进度信息。
-
parse_dates=False:指定是否要解析日期。
-
date_parser=<no_default>:用于解析日期的函数。
-
date_format=None:指定日期的格式。
-
thousands=None:指定千位分隔符。
-
decimal=’.’:指定小数点字符。
-
comment=None:指定注释字符。
-
skipfooter=0:指定要跳过的文件末尾的行数。
-
storage_options=None:用于云存储的参数字典。
-
dtype_backend=<no_default>:指定数据类型后端。
-
engine_kwargs=None:传递给引擎的额外参数字典。
注:read_excel 默认读取第一个表单(sheet_name=0),假设 data.xlsx 文件中只有一个表单,读取后的数据会存储在一个 DataFrame 中。
如果 data.xlsx 文件中有多个表单,可以通过指定 sheet_name 来读取特定表单的数据,例如pd.read_excel(‘data.xlsx’, sheet_name=‘Sheet1’)。
存储文件:to_excel()#单工作表
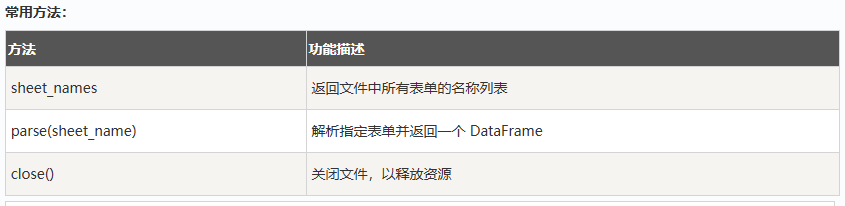
加载文件: pd.ExcelFile()
一个用于读取Excel 文件的类,它可以处理多个表单,并在不重新打开文件的情况下访问其中的数据。
excel_file = pd.ExcelFile(‘data.xlsx’)
写入文件:pd.ExcelWriter()
ExcelWriter 是 pandas 提供的一个类,用于将 DataFrame 或 Series 对象写入 Excel 文件。使用 ExcelWriter,你可以在一个 Excel 文件中写入多个工作表,并且可以更灵活地控制写入过程。
pandas.ExcelWriter(path, engine=None, date_format=None, datetime_format=None, mode=‘w’, storage_options=None, if_sheet_exists=None, engine_kwargs=None)
参数说明:
-
path:这是必需的参数,指定了要写入的 Excel 文件的路径、URL 或文件对象。可以是本地文件路径、远程存储路径(如 S3)、URL 链接或已打开的文件对象。
-
engine:这是一个可选参数,用于指定写入 Excel 文件的引擎。如果为 None,则 pandas 会自动选择一个可用的引擎(默认优先选择 openpyxl,如果不可用则选择其他可用引擎)。常见的引擎包括 ‘openpyxl’(用于 .xlsx 文件)、‘xlsxwriter’(提供高级格式化和图表功能)、‘odf’(用于OpenDocument 格式如 .ods)等。
-
date_format:这是一个可选参数,指定写入 Excel 文件中日期的格式字符串,例如 “YYYY-MM-DD”。
-
datetime_format:这是一个可选参数,指定写入 Excel 文件中日期时间对象的格式字符串,例如 “YYYY-MM-DD HH:MM:SS”。
-
mode:这是一个可选参数,默认为 ‘w’,表示写入模式。如果设置为 ‘a’,则表示追加模式,向现有文件中添加数据(仅支持部分引擎,如 openpyxl)。
-
storage_options:这是一个可选参数,用于指定与存储后端连接的额外选项,例如认证信息、访问权限等,适用于写入远程存储(如 S3、GCS)。
-
if_sheet_exists:这是一个可选参数,默认为 ’error’,指定如果工作表已经存在时的行为。选项包括 ’error’(抛出错误)、’new’(创建一个新工作表)、‘replace’(替换现有工作表的内容)、‘overlay’(在现有工作表上覆盖写入)。
-
engine_kwargs:这是一个可选参数,用于传递给引擎的其他关键字参数。这些参数会传递给相应引擎的函数,例如 xlsxwriter.Workbook(file, **engine_kwargs) 或 openpyxl.Workbook(**engine_kwargs)等。
利用ExcelWriter()类写入多个工作表并关闭保存
注: with ExcelWriter('output.xlsx')
as writer:
df.to_excel(writer, sheet_name='Sheet1')
用于自动关闭打开的文件
write =
pd.ExcelWriter('文件路径.xlsx')
df.to_excel(write,sheet_name =
"")
df.T.to_excel(write,sheet_name="")
wirte.save()
JSON
读取数据:pd.read_json()
read_json() 用于从 JSON格式的数据中读取并加载为一个 DataFrame。它支持从 JSON 文件、JSON 字符串或JSON 网址中加载数据。
df = pd.read_json(
path_or_buffer, #JSON 文件路径、JSON 字符串或 URL
orient=None, #JSON 数据的结构方式,默认是 'columns'
dtype=None, #强制指定列的数据类型
convert_axes=True, #是否转换行列索引
convert_dates=True, #是否将日期解析为日期类型
keep_default_na=True # 是否保留默认的缺失值标记)
存储文件:pd.to_json()
to_json() 方法用于将 DataFrame 转换为 JSON 格式的数据,可以指定 JSON 的结构化方式。
df.to_json(
path_or_buffer=None, #输出的文件路径或文件对象,如果是 None 则返回 JSON 字符串
orient=None, #JSON 格式方式,支持 'split', 'records', 'index', 'columns', 'values'
date_format=None, #日期格式,支持 'epoch', 'iso'
default_handler=None, #自定义非标准类型的处理函数
lines=False, #是否将每行数据作为一行(适用于 'records' 或 'split')
encoding='utf-8' #编码格式